Creating app reliability: the key to success in web3
Author: Suzanne Slaughter
Many teams’ web3 apps are doomed.
Why?
Because apps are totally dependent on nodes, and nodes are incredibly difficult to maintain. Some reasons:
- Node reliability can't be built in a vacuum; reliability must be accompanied by node scalability and data accuracy
- Nodes are not designed to be full-scale, production solutions
- Nodes are expected to do too many things
- Nodes require full-time maintenance
- Nodes' efficacy depends on successfully navigating unpredictably timed network upgrades or hard forks
These complications make nodes hard to manage and maintain.
But there are two architectural dimensions that significantly improve node reliability, or the ability for a user to successfully interact with your app when they need to:
- Heterogeneity: diverse and complementary systems that can handle different requests
- Redundancy: backup systems, so that if one system goes down, others will still be up
In web3, a lack of reliability can have detrimental outcomes.
Take a well known NFT marketplace using unreliable infrastructure...
Their platform was unstable, creating:
- Heavy engineering burden
- Degraded UX
- Over 190 hours of downtime in a single quarter
What was the impact?** $6M in lost revenue.**
Don't let it happen to you.
In this article, we’ll explain:
- Why maintaining node reliability is challenging
- Common node infrastructure patterns and why they fail
- How Alchemy accounts for reliability challenges and builds for reliability at scale
Why maintaining node reliability is challenging
There are five primary reasons why reliability is particularly hard to maintain in web3:
(1) Node reliability can't be built in a vacuum; reliability must be accompanied by node scalability and data accuracy
To create a highly functional app, you need reliability, combined with scalability and data accuracy.
- Scalability: the ability to continue interacting with the blockchain as traffic on your app** scales** 10x, 100x, 1000x or more.
- Data accuracy: the state when your app returns correct and consistent data to every single user.
(2) nodes are not designed to be full-scale, production solutions
Nodes were initially designed to be run by individuals for personal and small scale use cases. Although they’re expensive ($1000 / month), for that limited use case, they can create sufficient reliability, and maintain:
- Scalability; the request volume is predictably controlled, limiting any risks with required scalability
- Data accuracy; because there is only one node, there is no opportunity for data inconsistencies within nodes
However, a development environment is not a production environment, and production requires very different tooling.
(3)** **nodes are expected to do too many things
Nodes are expected to do an unbounded number of things, e.g., running peer-to-peer software, serving as a scalable database, executing arbitrary code, etc.
Nodes also have no “opinion” about what they should or shouldn’t do.
Together, this has two primary ramifications:
- Scalability; as you scale with increasing request volume, you need to spin up new nodes; and each new node must be built to include that long list of functionality, creating cumbersome inefficiencies and cost (again, on the cheap end, running a node will cost $1,000/mo).
- Edge cases; Because the node lacks basic protections, one query can singlehandedly crash your node.
(4) Nodes require full-time maintenance
On average, every 5 days, nodes may have issues from:
- Memory leaks
- Data storage issues
- Maximized CPUs
- Inconsistent peering
- Corrupted internal databases
- Transaction broadcasting issues
- Bugs + regressions
- 1 in 6 “stable releases” are broken
Each issue takes significant time to diagnose, troubleshoot and fix, and means significantly less time focused on your front-end user experience.
“Working with Alchemy has helped us save the equivalent of three full-time engineers, who otherwise would have to be heads down on infra maintenance, at all times.” - Evgeny Yurtaev, CEO and Co-Founder, Zerion
(5) Nodes' efficacy depends on successfully navigating unpredictably timed network upgrades or hard forks
Network upgrades and hard forks happen on a protocol’s schedule, not yours. Each one requires significant preparation, and getting it wrong can mean nodes crash, with detrimental impact.
“Before we integrated with Alchemy, we ran our own blockchain infrastructure. This approach was impossible to maintain and scale without issues. Any industry-wide update would take us hours to implement and caused headaches across the board.” - Evgeny Yurtaev, CEO & Co-Founder, Zerion
Common infrastructure architecture patterns and why they fail
Running reliable node infrastructure is intrinsically challenging, and a lot of common web3 architecture is ineffective at creating reliability:
Running a single node
It's more simple to set up, but subject to a single point of failure, lacking both heterogeneity and redundancy. A single node’s uptime is measured as low as 72%, and scaling a single node is highly inefficient.
Running a node with a backup
This creates slightly more redundancy than a single node, but still no heterogeneity (no diversity in systems), and often, a request that takes down the first node will take down the second node too. Scalability issues still exist, and you’ve introduced data accuracy issues, meaning the nodes will return different responses, as most systems are unable to guarantee that each node is on the same block head (or even the same chain).
Load balancing across a fleet of nodes
This model creates more redundancy, but still no heterogeneity. Data accuracy and scalability issues persist (a series of retries will take out an entire fleet of nodes).
| Reliability | Scalability | Data accuracy | |
|---|---|---|---|
Running one node | Lacks heterogeneity and redundancy | Cumbersome to spin up new nodes | Yes! Has data accuracy |
Running one node with a backup | Lacks heterogeneity and redundancy | Cumbersome to spin up new nodes | No data accuracy |
Load balancing across a fleet of nodes | Lacks heterogeneity and redundancy | Cumbersome to spin up new nodes | No data accuracy |
Nodes often go down and are really,** really cumbersome to fix.**
If it’s not clear yet, many “solutions” for connecting to the blockchain don’t sufficiently provide heterogeneity or redundancy, and because of that, ultimately fail. Failure has severe ramifications.
“Before Alchemy, we were plagued with managing backend infrastructure that exhausted unnecessary development resources - and other developer platforms were insufficient in the breadth of solutions they offered. Node-related incidents made up almost all of our on-call incidents.” - Brad Bayliss, Lead Technical Manager, Enjin
Nodes can require days or weeks of recovery time to get up and running again. These issues are expensive, hard to solve and require heads down work across the team.
In 2019, BlockCypher tried to navigate Ethereum’s Constantinople Hard Fork. They ran into an error of missing data, and couldn’t diagnose the root cause. They suffered from over a month of downtime, and eventually had to essentially restart from scratch.
Don’t let it happen to you ;)
The more heterogeneous and redundant your web3 infrastructure is, the more reliable it will be.
How Alchemy builds for reliability at scale
“Without question, Alchemy has been the only provider with a comprehensive set of tools that enables us to scale seamlessly, with uninterrupted reliability, while making thousands of calls each day.” - Kyle Gusdorf, Software Engineer, Decentral Games
Supernode is a combination of custom, scalable and distributed systems that enable reliability and scalability, while allowing our API to act as a single node, thereby ensuring data accuracy.
Supernode achieves both redundancy and heterogeneity with scalable and diverse systems
Redundant and heterogeneous systems to minimize data requests on nodes
Web2 infrastructure creates reliability and scalability by removing data storage from servers and creating external storage centers.
However, because of the unique nature of node architecture, removing data storage from nodes is essentially impossible.
To create reliability and scalability, Supernode uses advanced architecture, called secondary infrastructure, to replicate nodes’ data.
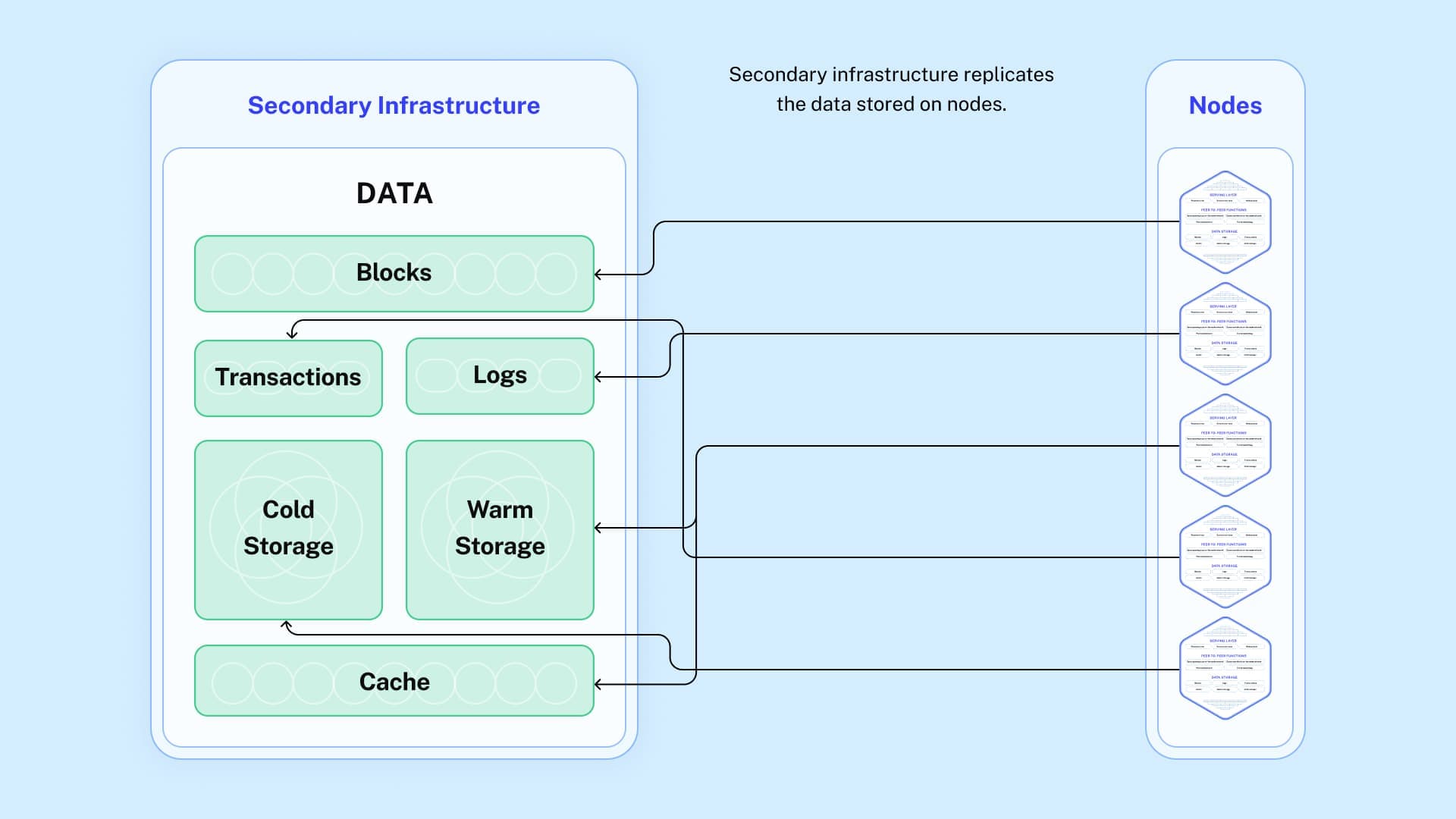
Vox Nodi, Supernode’s coordination layer, runs constant system checks to ensure the secondary infrastructure has the latest data, and therefore, any requests for data, e.g., block number, txn logs, txn receipts will be accurate.
By routing requests to secondary infrastructure first, the nodes are protected and their “workload” is reduced.
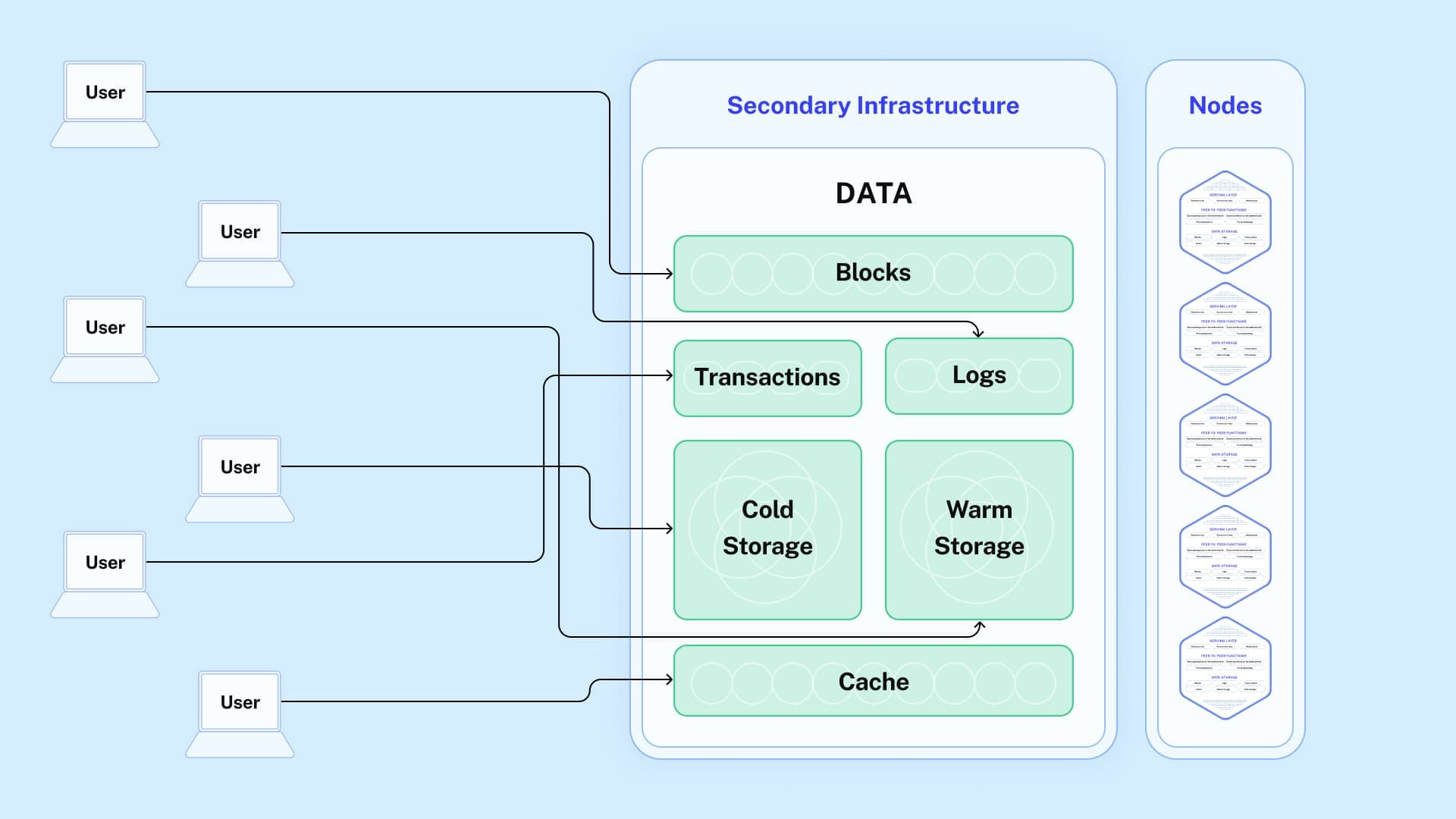
Most requests can be handled by secondary infrastructure, and only edge cases will be routed to nodes.
Let’s take an example:
Users want information about various data types and blocks:
- User 1 asks for Transactions data up to Block 82
- User 2 asks for Logs data from Block 85
- User 3 asks for Blocks data from Block 92
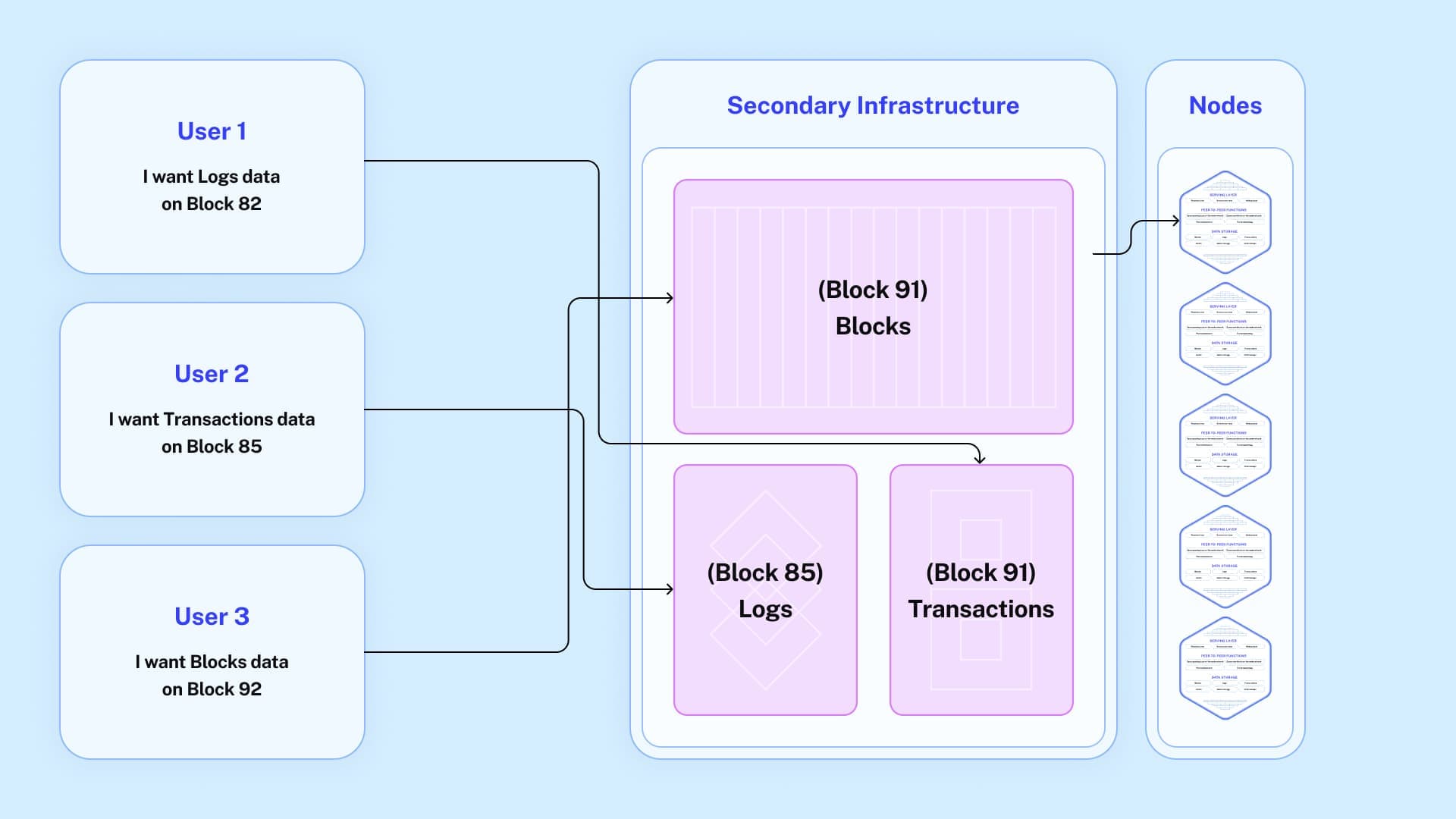
User 1’s request can be served by the secondary infrastructure system. (Importantly, if a request like this were to hit a node directly, the node would crash, whereas, the secondary infrastructure system can handle this load seamlessly).
User 2’s request can also be served by the secondary infrastructure.
User 3’s request cannot be served through secondary infrastructure, because the system does not yet have the latest Blocks data from Block 92. User 3’s request will now be served from the nodes.
In this example, the experience for Users 1, 2 and 3 is the exact same. There is no difference in downtime when a request is responded to via secondary infrastructure or directly from the nodes. But by routing requests to the secondary infra system first, the nodes are protected and their “workload” is reduced.
"Alchemy has allowed us to eliminate having to use secondary / back-up infra. Alchemy never goes down, and their uptime is super consistent. Their platform works perfectly for us.” - Johnny Rhea, Co-Founder & CTO, Element.Fi
Redundant and heterogeneous systems to execute code
Because the Ethereum Virtual Machine (EVM) is Turing complete, you can request that nodes execute code. Because nodes can’t self-regulate, there is constant potential for an arbitrary request to bring down an entire node fleet.
To protect against this, Alchemy de-duplicates ands stores all requests our system has previously responded to.
This means that only a uniquely new request will be run on the nodes, and otherwise, the vast majority of requests can be executed by these storage systems.
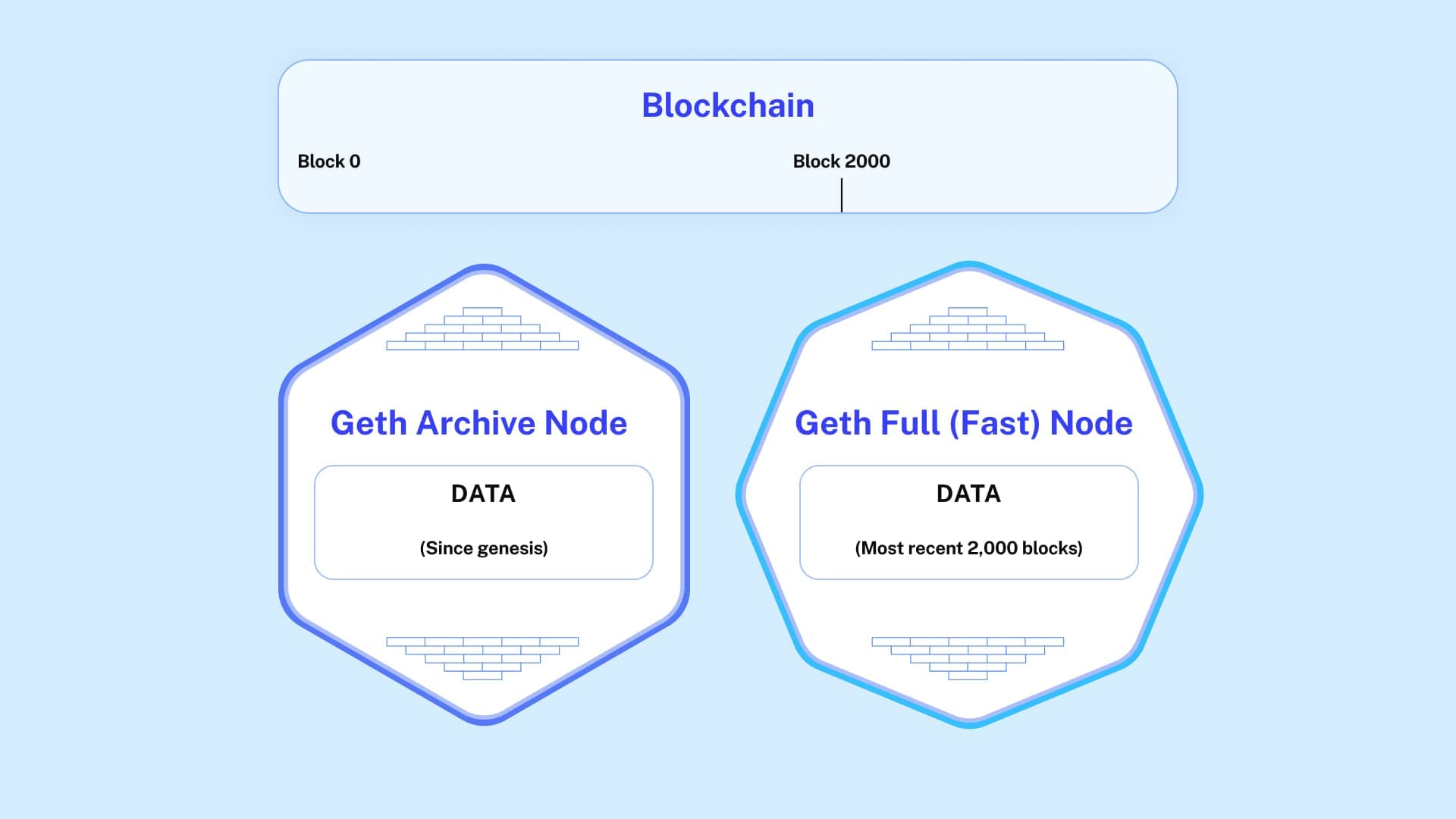
| Node Type | Data Coverage |
|---|---|
Geth Archive Node | Since genesis |
Geth Full (Fast) Node | Most recent 2,000 blocks |
Heterogeneous nodes, specialized for different requests
In addition to secondary infrastructure systems, Alchemy adds heterogeneity with distinct node types. In the outlier scenarios when secondary infrastructure can’t respond to a request, the system defaults to the most scalable node.
Alchemy runs multiple types of nodes, including:
- Light: downloads only the block headers, the minimum data needed to transact on the network. Light nodes can efficiently interact with the network and save megabytes of bandwidth and gigabytes of storage, but they’re limited in that they don’t have access to full data.
- Full: has everything it needs to verify that the blocks on the network are correct, and can interact with any smart contract and deploy its own. Full nodes require significant computing and bandwidth resources.
- Archive: goes one step further than a full node. While a full node trims entries that it no longer needs to verify, the archive node maintains everything (terabytes of extra data). These details are great for querying information more efficiently and handy for a few applications, but are excessive in most cases.
- Debug: debug nodes go even further than an archive node, storing the most information of any node type, so you can step through the execution of a smart contract in extreme detail.
Distinct properties of node types make them good at different things, so if one node can’t answer a request, the others are likely still healthy and well-suited to respond.
For example, if there is a request for the newest data, which may not be recorded in secondary infrastructure yet, that request can be routed to a fast node, and the archive node will be “protected”, since sifting through the archive node’s data would be significantly more expensive.
To make it easier to spin up new nodes as needed, the Supernode system takes “snapshots” of the nodes, so that to create a new node, the system can start from the most recent “checkpoint,” significantly shortening the the syncing process.

Build vs. Buy: Blockchain Infrastructure
Before you hire an infra team, read this: building in-house can cost $850K–$1M+ a year before you serve a single production request. See the full cost breakdown.
Heterogeneous clients to mitigate the impact of bugs
Lastly, Alchemy runs different implementations of the Ethereum client, including geth, Erigon and Parity. This essentially triples the backend maintenance work required, but it is hugely valuable in service of heterogeneity: the chance that these clients have the same bug is essentially zero.
Creating reliability through redundancy and heterogeneity
At Alchemy, we’ve spent hundreds of thousands of hours engineering Supernode, a complex set of systems, built from the ground up, to be heterogeneous and redundant, drastically increasing our fault tolerance and ensuring we can reliably respond to any blockchain request.

"Infrastructure that’s both reliable and scalable, so that we can stay up when our customers need us most - that’s huge for Collab.Land. Alchemy is the GOAT here.” - Raymond Feng, CTO, Collab.Land

It’s taken us years to build the complex, interdependent systems that make this reliability possible. Building to control for reliability is extremely challenging but leveraging reliable infrastructure is crucial for the success of your app.
As you explore infrastructure options, one of the first things you should be asking a provider is: “How heterogenous and redundant is your infrastructure? And what evidence can you show me that proves your systems’ reliability?”
Your apps’ success is contingent on this choice. Let us know how we can help!
Alchemy Newsletter
Be the first to know about releases
Sign up for our newsletter
Get the latest product updates and resources from Alchemy
By entering your email address, you agree to receive our marketing communications and product updates. You acknowledge that Alchemy processes the information we receive in accordance with our Privacy Notice. You can unsubscribe anytime.

Related articles

Blockchain RPC infrastructure evaluation guide for enterprises
Choosing the wrong blockchain RPC provider can mean costly migrations and poor performance. Use this enterprise evaluation framework to ask the right questions before you commit.

Photon on Alchemy: compressed Solana data, standard RPC
Photon / ZK Compression read methods now run on Alchemy’s standard Solana RPC URL—one endpoint, production-scale latency, and a migration that is a URL change from other Photon-compatible providers.

How the edge layer powers faster RPC on Alchemy
Inside the Alchemy Edge Proxy: how a custom bare-metal ingress layer makes blockchain RPC up to 7.5x faster across 100+ networks, with no customer migration.