Data Accuracy: The Little Known, Endemic Problem in Web3
Author: Alchemy Team
A well known NFT team lost tens of thousands of users because they were showing their users conflicting information (example above).
One of the largest DeFi protocols lost $2M from troubleshooting bugs that were creating frontend errors for users. Because the protocol couldn’t pinpoint the root cause, the issue wasn’t resolved for weeks.
These two scenarios stem from the same problem: a lack of accuracy in node infrastructure, which is a prolific problem in web3.
As an engineer, founder, product manager or even user, if node accuracy isn’t on your radar already, you need to make it a top priority in order for your app to succeed.
A bit of background
Blockchains are run by nodes that communicate in a peer-to-peer network. It’s this structural element that enables decentralization, one of the fundamental value propositions of web3: instead of relying on a central intermediary, thousands of nodes record transactions by trustlessly propagating information to each other.
To serve users correct and consistent results, the network of nodes has to agree about the most recent state of the blockchain. This is extremely challenging in a peer-to-peer network, because information doesn’t reach each node at the same time.
This means that when a person interacts with a dApp reliant on nodes to serve them data:
The nodes don’t always serve the same data ➡️
The user won’t always get back what they expect
More often than not, when users receive unexpected or conflicting information that they can’t rationalize, it’s because there is a lack of accuracy among the nodes they’re using.
At Alchemy, we define accuracy as the state when a person interacts with a dApp and receives correct and consistent data in return.
In this article, we’ll explain:
Why accuracy is a web3-specific problem
The limitations of solving accuracy with a single node
The limitations of solving accuracy with a load balancer
How a lack of accuracy can create widespread problems for an app
The secret sauce to how Alchemy’s Supernode solves blockchain accuracy
Accuracy exists when a person interacts with a dApp and receives correct and consistent data in return
In web2, centralized systems make accuracy an easy problem to solve, because information can only come from one source. But the web3 distributed system causes a myriad of new and complicated issues, including:
Complex implementation
Challenges ensuring that information gets to the furthest participants in the network (it literally takes longer for information to reach nodes further away in a network)
Challenges with network coordination
All of these challenges, which can create a lack of accuracy among a group of nodes, can lead to:
Serving broken experiences
Losing customers
Losing time and money by retroactively fixing the problem
"Every state issue you could think of on CryptoKitties happened. If nodes were out of sync, the user experience and entire dApp would be messed up." - Eric Lin, Dapper
The Problems With Running a Single Node
If the problem of data accuracy stems from communication among several nodes, you may decide to run a single node yourself.
Let’s say you are running your own single node, and a user makes a call to your dApp:
They ask for the latest block
Your node tells them the latest block is 4
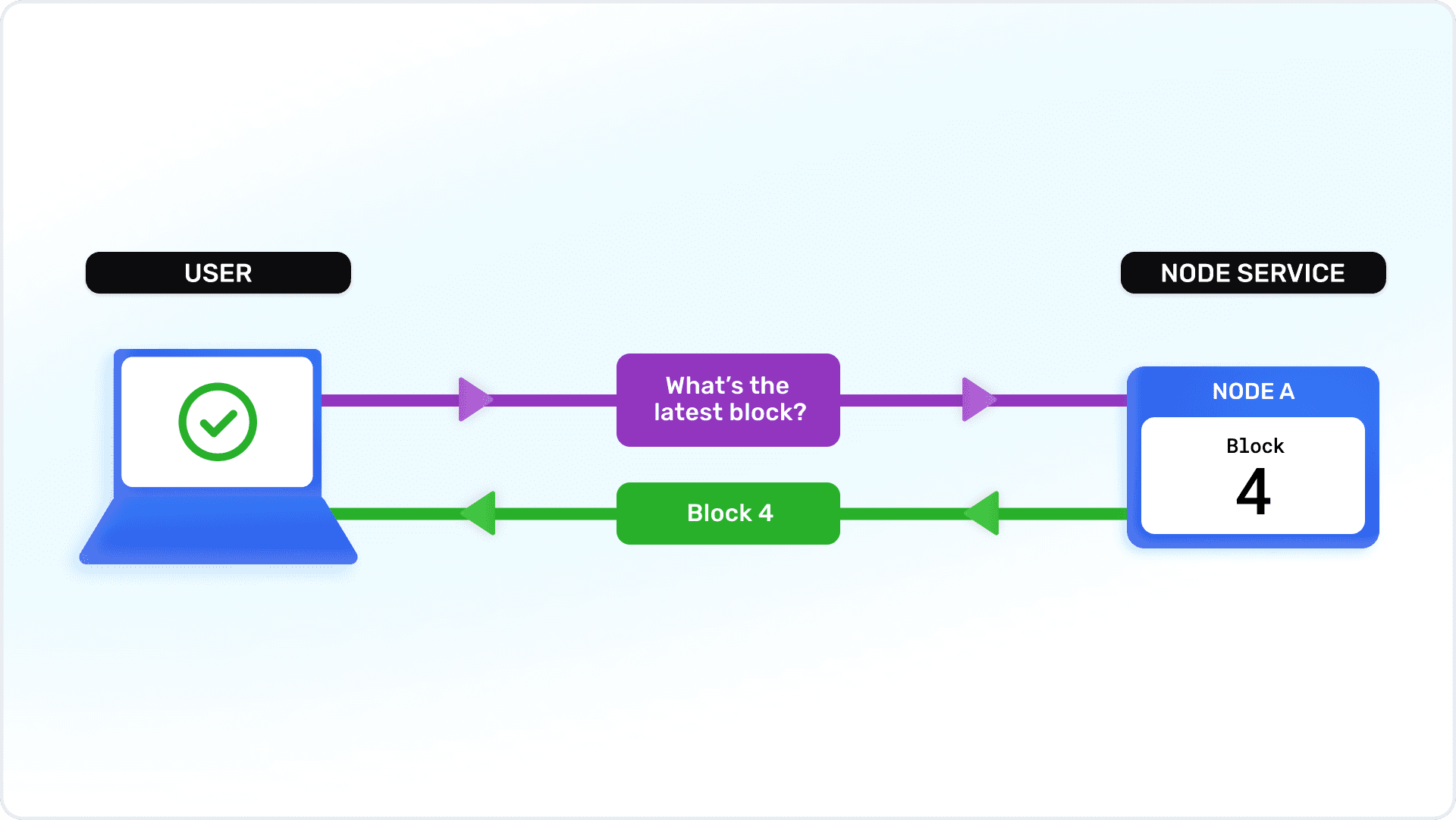
✅ This works!
But there’s a catch.
It will only work up to a certain point.
Running traffic through a single node will drastically inhibit your app’s scalability and reliability:
Scalability: If your dApp has 100 users today, but usage demands it scales 10x, one node will not effectively manage the increased request load
Reliability: If you are dependent on one node, then when that node goes down, your dApp will go down, too. And because nodes are notoriously unreliable, with just one, you will have much less uptime than you need (we’ve measured uptime from a single node to be as low as 72% in some cases).
The time it would take for your team to spend on node maintenance is time they can’t spend on building products and experiences for your customers.
"Working with Alchemy has helped us save the equivalent of three full-time engineers, who otherwise would have to be heads down on infra maintenance, at all times." - Evgeny Yurtaev, CEO & Co-Founder at Zerion
Ok, so you’ve realized one node is insufficient for your business needs. So what may you do next?
The Problems with Using a Load Balancer
You may want to try an infrastructure provider that uses a load balancer to manage traffic across multiple nodes; this is a super common infrastructure design in web3.
Load balancing is a horizontal scaling mechanism, originally utilized in web2. Think of load balancing like choosing the shortest line at the grocery store - the load balancer will direct your dApp’s traffic to the node with the shortest line.
Take a look at the example below.
A user makes a call to your dApp:
They ask for the latest block
Via Node A, your dApp tells them the latest block is 2
Then, the user asks again to confirm:
This time the query is routed to Node B
Via Node B, your dApp tells them that the latest block is 4
Because the system is still routing each request through a single node, and at any given point, that node may not have the latest information, the results are often incorrect. Your users will be served conflicting results that are impossible to reason about.
Load balancing creates more scale and reliability than a single node can maintain, but it comes at the expense of accuracy.
When traffic is routed through a load balancer, nodes may have different information about:
Latest blocks
Most recent transactions
Pending transactions
These problems can mean that:
Requests fail
Applications fail
A single user will see conflicting results for the same request
Multiple users will see conflicting results for the same request
Still not convinced this is a big problem? Read on.
How a lack of accuracy causes major problems
Let’s say Isaac wants to join a DAO, and to do so, he needs to purchase their token.
Isaac asks a Decentralized Exchange (DEX): “DAO token still available?”
The DEX’s infrastructure provider routes Isaac’s request to Node A.
Via Node A, the DEX tells him: “Yes, tokens are still available.”
✅ Tokens are available!
Isaac goes to make his purchase.
The DEX’s infrastructure provider routes Isaac’s request to Node B.
Via Node B, the DEX tells him: “Transaction failed.”
Because the DEX was using an infrastructure provider that was load balancing across nodes (a super common web3 scaling mechanism), when Isaac confirmed that the token was still available, Node A returned information that in this case was stale.
This underscores the key point: at a given moment in time, the information from an individual node, which is where information always comes from when using a load balancer, cannot be depended on.
That node may not have the most recent information, and if that is the node that responds to your request, your transaction (or subsequent transactions) will likely fail or exhibit unexpected behavior.
Accuracy issues cause a wide range of failure states
What happened to Isaac is one of many failure states caused by a lack of node accuracy.
Let’s take a look at a couple more potential failure states:
1. Smart contract executions return conflicting answers when there should be only one factual result. For example:
User asks: “Who owns this Bored Ape?”
API returns: “Alice”
Then user asks: “Tell me the apes Alice owns?”
API returns: “Alice doesn’t own any”
Why’d this happen? With infrastructure reliant on a load balancer, the state of smart contracts, and thus what happens when you execute them, will be different depending on which node handles the request.
2. A dApp returns an incorrect “nonce” (a unique identifier for each individual transaction from any given wallet address), causing subsequent transactions to fail. For example:
User completes transaction 1 with nonce 100
User asks: “What’s the next nonce?”
API returns: 100 (this should be impossible, since nonce 100 was already completed)
The next transaction will be automatically rejected
Why’d this happen? With inaccurate infrastructure, pending transactions can end up on only a single node, so when you try to get information about the state of those pending transactions or the wallets that sent them, there is very often missing or misleading data returned.
These failure states are insidious, impossible to reason about, and will severely impact the health of your app
Some things that may happen:
You may ingest inaccurate data which will corrupt your databases, requiring time and effort to fix.
Take Origin, for example. RPC errors and debugging were ubiquitous with their first infrastructure provider, and debugging the errors was time consuming for their team.
They found that one node would answer a request, but that node was a few blocks behind a different node that answered another request.
These state issues were virtually impossible to troubleshoot, and once they did identify the root cause, they found the issue had corrupted their entire system.
Because there are no error messages or failure codes for these issues, you a) can’t proactively account for them in your code and b) will spend hours debugging them when they happen; this will be just as confusing for your users:
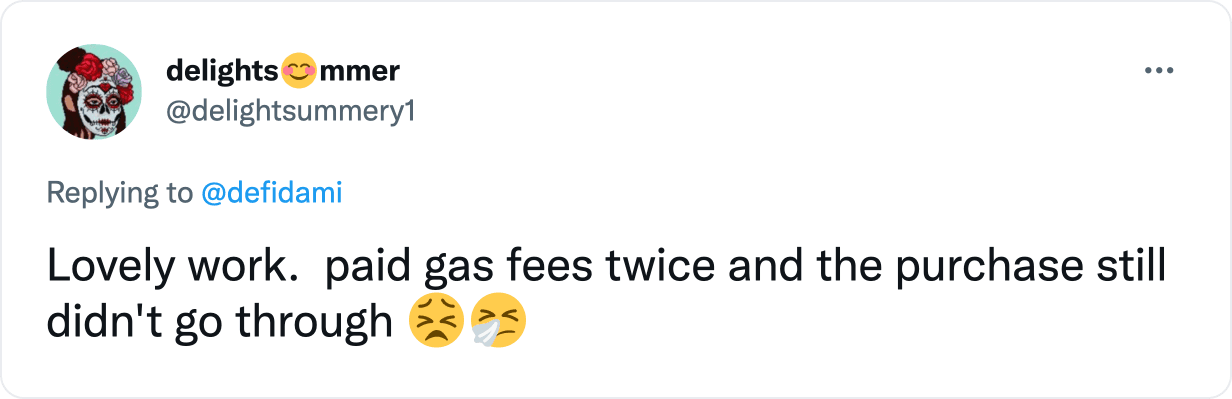
Users may send transactions based on stale data and that are therefore guaranteed to fail; they will lose gas fees as a result:
Users may see conflicting UIs on your dApp, consecutively reflecting that a transaction was or wasn’t successful. They will attribute this failure to your dApp’s frontend experience:
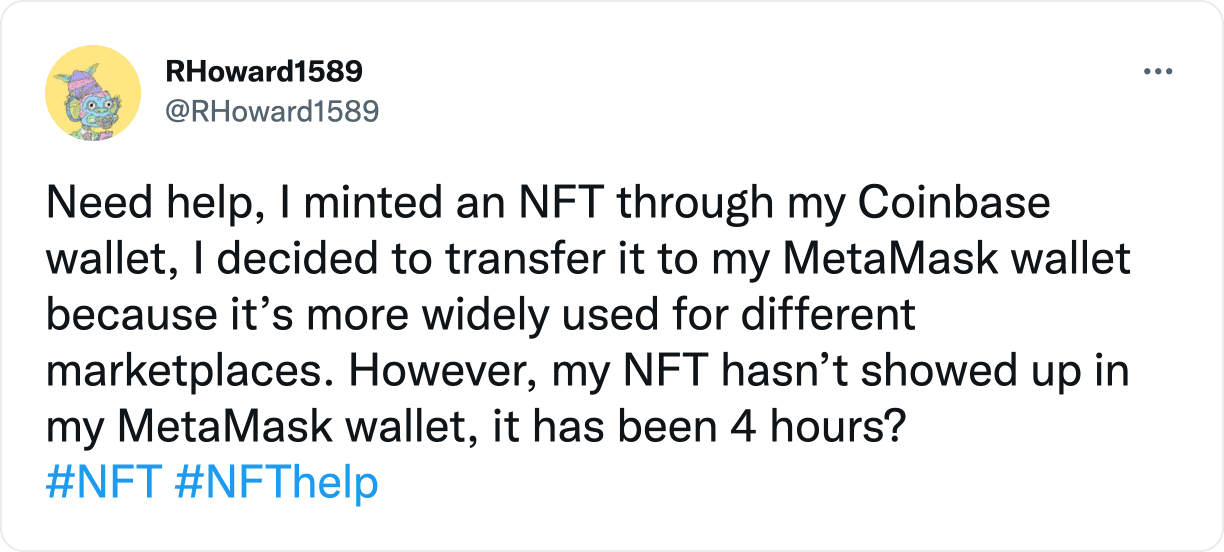
Users may overpay because they think that a transaction wasn’t successfully mined, and they try again; in reality, the original did go through but wasn’t accurately reflected:
Building for Accuracy
If it’s not clear yet, in blockchain networks, a lack of accurate infrastructure can have a very negative impact on your dApp and users.
You need to work with an infrastructure provider that is:
Thinking about accuracy as a fundamental priority
Who has a sustainable system, distinct from load balancing, to maintain accuracy when your dApp scales
Benchmarking Node Providers
We have compiled data that benchmarks accuracy across a few well-known node infrastructure providers. Use this tool to benchmark accuracy yourselves, too.
In our tests, we query the JSON RPC method eth_blockNumber a total of ~1,072,000 times to get the latest block number from each provider over a period of 24 hours. This is one simple example for benchmarking data inaccuracy. There are many others which tend to fail more often, and more catastrophically.
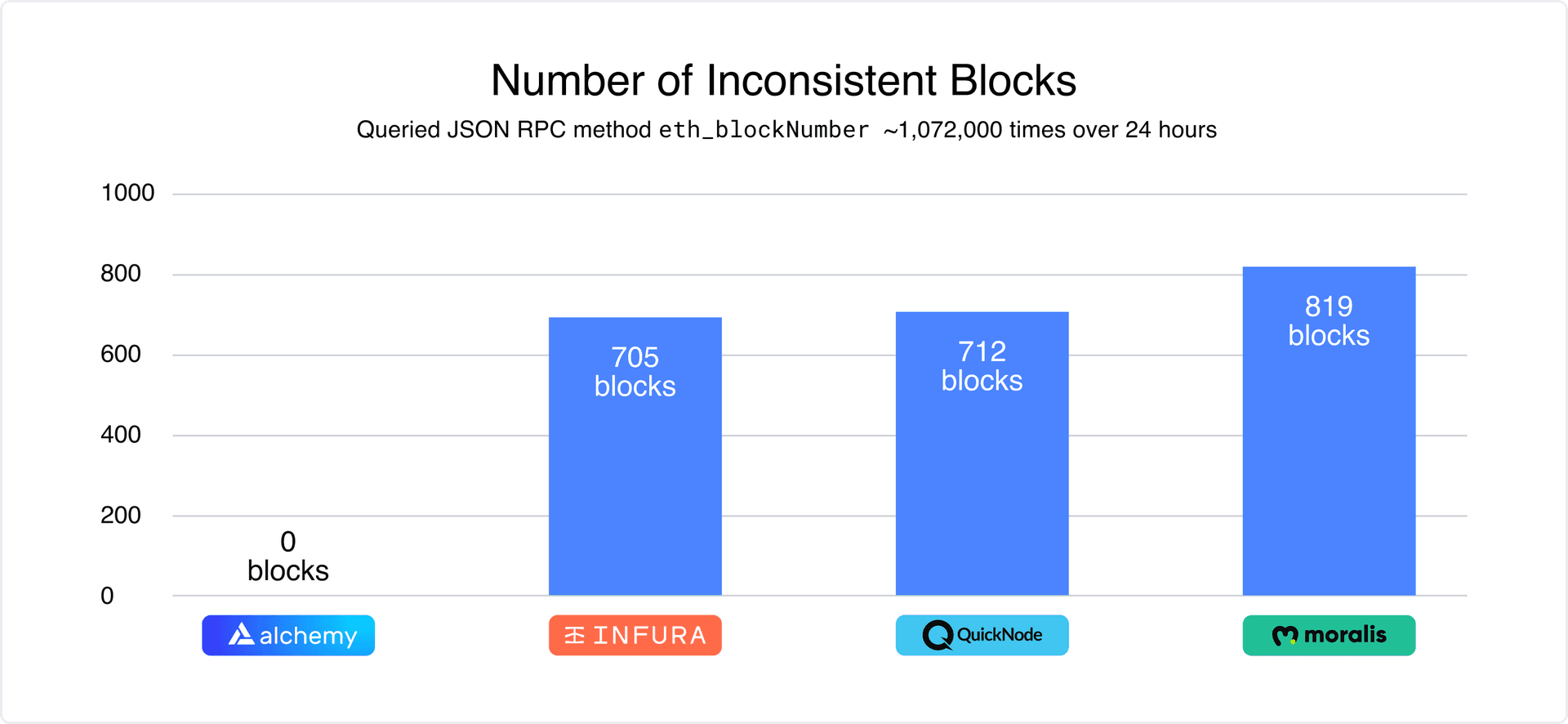
Note In our sample dashboard snapshot, we query and log data accuracy for a single day.
*Full methodology details in appendix.
What can you do to get accurate data?
"Alchemy resolved the consistency issues that had previously reared their head, removing 98% of user complaints and significantly improving Augur’s user experience and adoption." - Augur CTO Alex Chapman
In service of ensuring accuracy for your dApps and your customers, Alchemy has invested hundreds of thousands of engineering hours and developed hundreds of unique innovations to create Alchemy Supernode, the fundamental product that ensures consistent data accuracy, with the scalability and reliability benefits of multi-node infrastructure.
Supernode is much more than just a bunch of connected nodes - in fact, that’s just a fraction of what the Supernode system is. Supernode is a combination of custom, scalable and distributed systems that essentially allow our API to act as a single node, which solves all of the accuracy issues we’ve discussed.
How does this work?
We’ve built out an explicit consistency layer called Vox Nodi (the voice of the nodes). Vox Nodi’s responsibility is to guarantee that any blockchain request that we’re helping to serve will return a consistent result.
This works by essentially running a consensus algorithm across our infrastructure, where each piece of the infrastructure can vote on the correct state of the blockchain.
By correctly routing and tweaking queries, this system ensures that despite various nodes having different views of transaction data at any given time, the results are always consistently accurate.
Simply put, Vox Nodi guarantees that any request to our API is returned quickly, reliably, and with 100% accurate data.
And Supernode still enables developers to scale infinitely and reliably, because rather than an individual node, there is a full, distributed blockchain engine responding to each request.
In short, it is not a load balancer.
Implications & Conclusion
There are many different dimensions to consider when choosing how to connect your dApp to the blockchain: A provider’s ability to deliver accuracy should be the number one on your list.
At Alchemy, accuracy is a top priority. Get started on Alchemy for free today.
-
Appendix
Benchmarking Methodology
In thinking about benchmarking accuracy, we started from first principles and tested one of the most basic Ethereum RPC calls: eth_blockNumber.
As a refresher, eth_blockNumber returns the Ethereum network’s latest block number, and in a decentralized network, the block with the highest block number contains the most recent transactions.
Because of this, in normal network conditions, calling eth_blockNumber from a single node/node provider should only return block numbers that ascend in value. Any inconsistency in ascending data is indicative of a reversion or, when it happens more frequently, of potential provider data inaccuracy.
Note that this is different from a ‘reorg’, where a new longest chain replaces existing data on a node. ‘Reorgs’ will always have at least as many blocks as the data already on a node, so if we see block number go backward we can know definitively say that it’s caused by broken infrastructure.
To understand how we measure misaligned data, let’s assume that we have the following sequence of block numbers after pollingeth_blockNumber a total of 13 times.

Given this sequence, we find a total of 5 errors at block indices 6, 7, 9, 10, & 11. What this means is that at blocks 6, 7, 9, 10 &11, the returned blocks did not follow the expected sequence of ascending values, evidencing some underlying data accuracy issue.
NOTE: Once we record that the node provider is on block number 2, we assume that any subsequent values of 1 are incorrect and equivalent to the provider time-traveling and providing current block value that is 1 block late. Similarly, once we record that the node provider is on block number 3, any instances of blocks 1 or 2 showing up are now misaligned. To simplify this benchmarking test, we explicitly measure data accuracy from individual providers themselves and do not cross-compare block data between different providers.
Alchemy Newsletter
Be the first to know about releases

Related articles

Introducing Prices API
Save development time with our new API for real-time and historical token prices.

New Integrations for Rollups partner: Parsec
Say goodbye to confusing block explorers. Parsec brings context and visual transaction flows to your rolllups.

Deeper application insights at lower costs
By re-architecting back end infrastructure, Alchemy has passed up to 3x efficiency savings to you for four key debug_trace methods.