
What is the data availability layer?
Written by Alchemy
The core tasks of modular and monolithic blockchains include executing transactions, achieving consensus on transaction ordering, and guaranteeing the availability of transactional data. The last part—data availability—is critical for blockchains and represents the focus of this article.
Data availability refers to the idea that all transaction-related data is available to nodes on the blockchain network. Data availability is important because it allows nodes to independently verify transactions and compute the blockchain’s state without the need to trust one another.
This guide will explain in detail what data availability means and why solving the “data availability problem” matters. You’ll also learn the role data availability layers play in scaling blockchains and the different solutions proposed for solving the data availability problem.
What does data availability mean?
Data availability in blockchains refers to the ability of nodes to download the data contained within all blocks propagated through a peer-to-peer network. Understanding data availability requires a grasp of current block verification processes in blockchains.
How does block verification work?
First, the block producer will:
- Take transactions from the mempool
- Produce a new block with those transactions
- Broadcast the new block to the P2P network to be added to the chain
A block producer is called a “miner” in a Proof-of-Work network and a “validator” in a Proof-of-Stake network.
Next, the** validating nodes** (aka full nodes) will:
- Download transactions from the newly proposed block
- Re-execute the transactions to confirm compliance with consensus rules.
- Adds the block to head of the chain once the network deems the block is valid
The following illustration uses Bitcoin as an example of block verification:
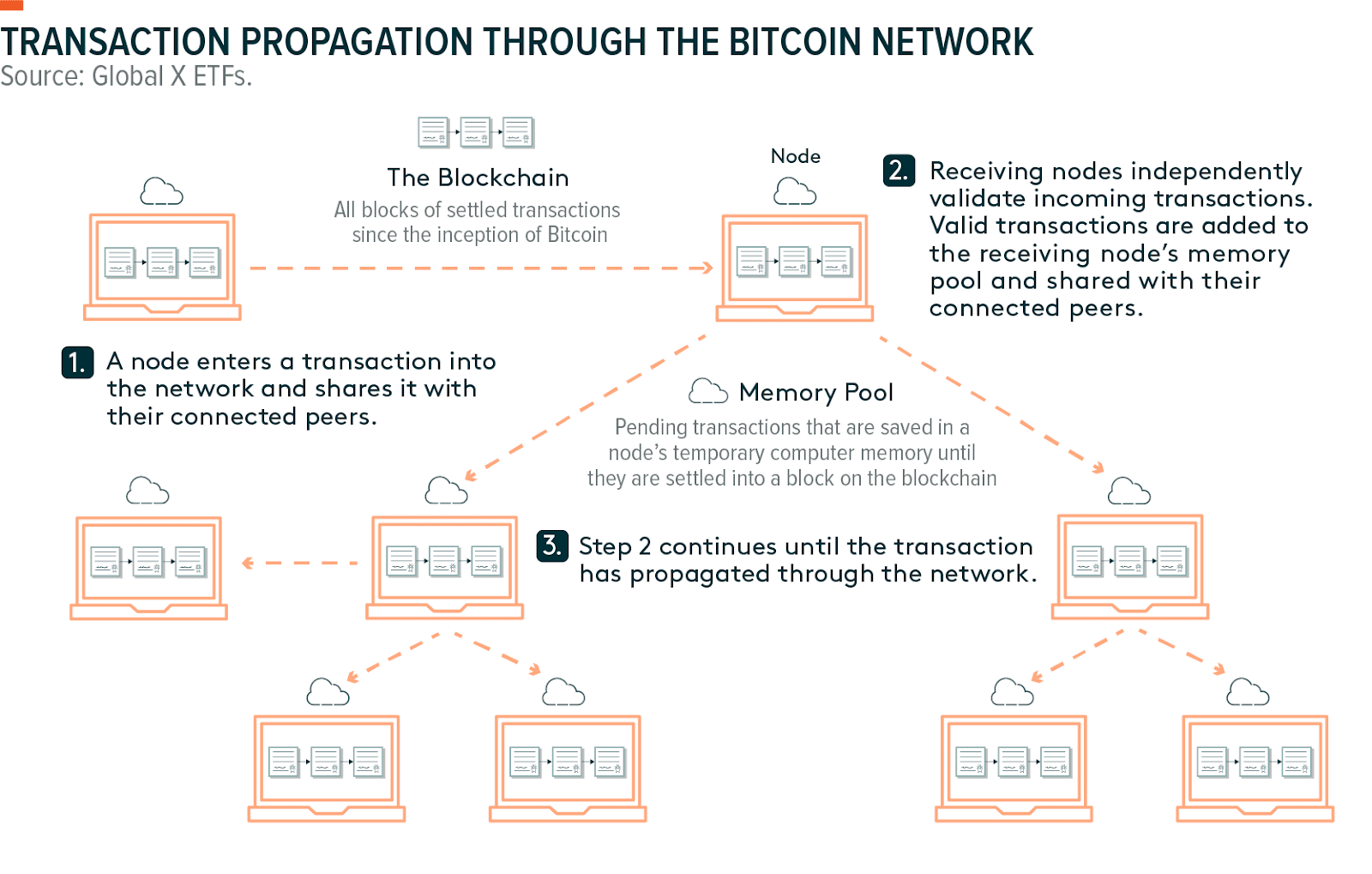
But what if a block proposer refuses to publish transaction data and only broadcasted the block headers, which contain metadata about transactions, but not the transactions themselves?
In such a scenario, full nodes would be unable to check the integrity of proposed blocks. Moreover, light nodes that only download block headers could be easily tricked into accepting invalid blocks
To avoid this problem, blockchains—especially monolithic chains—require block proposers to make block data available to the rest of the network.
Beyond enabling security, data availability rules encourage “trustlessness”: peers can independently verify transactions and blocks instead of trusting others in the network.
What are the challenges of data availability?
The challenges presented by needing data availability are: requiring nodes to download and verify data reduces throughput, and using on-chain storage for an increasingly large amount of information limits the number of entities who can run node infrastructure.
Monolithic blockchains ensure data availability by redundantly storing state data on multiple nodes so that a peer that needs such data only has to request it from another peer. But this naive implementation of data availability has a problems.
Forcing a large number of network nodes to download, verify, and store the same data massively reduces throughput for blockchains. This is the reason that Ethereum can only process 15-20 transactions per second and that Bitcoin’s processing speed is around 5-7 transactions per second.
On-chain data storage also leads to exponential increases in the size of the blockchain, which further increases hardware requirements for full nodes that need to store an ever-increasing amounts of state.
Rising costs of high-spec hardware tends to drive down the number of individuals willing to run nodes, which directly increases the risk of centralization.
Data availability and blockchain scaling
Data availability is also relevant in the context of blockchain scalability. Modular chains are often designed to scale throughput by separating data availability from consensus and execution. Under this arrangement, nodes are not required to store blockchain data, removing some of the constraints described in the previous section.
Nevertheless, the network still needs to guarantee that all block data is available to interested parties. This forms the basis of the data availability problem: “How can we know that the data behind each block was published without having access to the entire block?”
We’ll discuss solutions to the data availability problem in a later section. For now, let’s explore the concept of a “data availability layer” and its implications for blockchains.
What is the data availability layer?
In blockchains, a data availability layer is a system that stores and provides consensus on the availability of blockchain data. The ‘data availability layer’ refers to the location where transaction data is stored.
There are two types of data availability layers:
1. On-chain data availability layer
This is the standard approach among many blockchains, in which data is stored on-chain by the nodes who execute transactions. While this ensures high data availability, it limits decentralization and scalability.
2. Off-chain data availability layer
This approach requires storing transaction data outside the original blockchain network. An off-chain data availability layer may be another blockchain or any data storage system chosen by developers. In this case, the data availability layer focuses on storing data, not execution.
How does the data availability layer help Ethereum scale?
Sharding is an approach to blockchain scaling that involves splitting up a network into several sub-chains operating in parallel. Nodes in each sub-chain handle different tasks with the goal of achieving efficient use of computational resources.
Ethereum’s current scaling roadmap includes plans to implement data sharding—a system in which various clusters of nodes store distinct pieces of data. There will be 64 shard chains operating independently, with nodes only downloading data posted to their assigned shard. This means full nodes no longer have to store the same data, as currently happens.
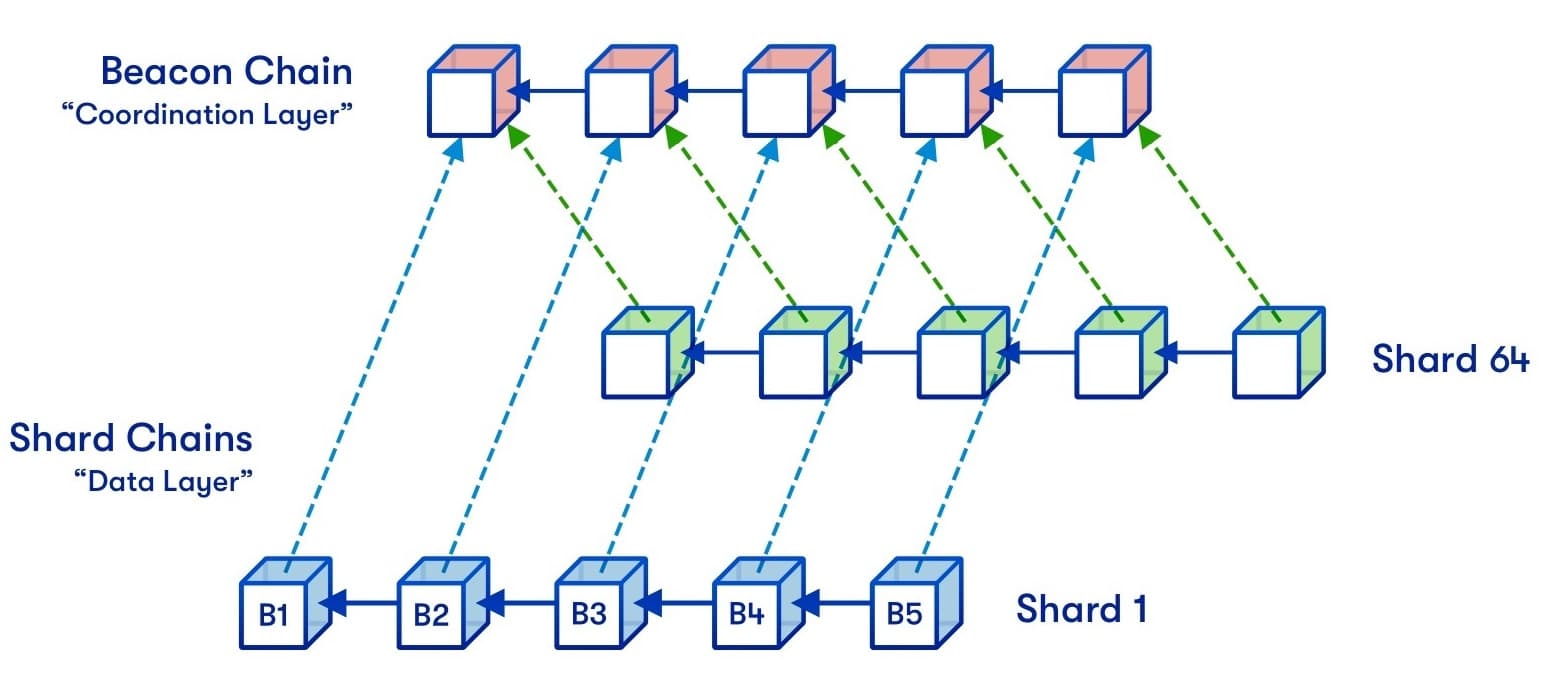
With sharding, Ethereum will employ multiple data availability layers instead of storing state data in one location. Blocks will not have to propagate throughout the network, and only a limited set of nodes will be required to verify each block's data. This directly translates to scalability because the network will be able to process transactions faster.
Moreover, storing data between multiple layers further decentralizes Ethereum.
Full nodes currently store the entire blockchain, which is roughly 1TB of data, per recent statistics, but will only need to store 1/64 of chain data with 64 shards in operation. This would potentially reduce storage requirements for full nodes and increase the number of validators on Ethereum.
How does the data availability layer work with rollups?
Rollups scale Ethereum by moving computation and state storage away from Ethereum’s execution environment: the Ethereum Virtual Machine. The EVM only accepts results of off-chain computation and applies them to its state without having to re-execute transactions, thus improving processing speeds and lowering costs.
What makes rollups safer than other Ethereum scaling solutions, including sidechains or Plasma, is their reliance on Ethereum for data availability. In addition to publishing transaction results on Ethereum, optimistic rollups and zero-knowledge rollups also publish transaction data on Layer 1 as CALLDATA.
Block data posted from a rollup to Ethereum is publicly available, allowing anyone to execute transactions and validate the rollup chain.
It also promotes censorship resistance because the posted data can be used by prospective block producers to reconstruct the chain’s state and start producing new blocks. No single Layer 2 operator can arbitrarily freeze the chain and censor users on the rollup due to this measure.
With the data availability layer providing security, rollups can optimize for scalability. For instance, a rollup can choose large blocks and faster block times to speed up processing speeds.
While this increases hardware requirements for nodes (most rollups have a few “supernodes” executing transactions), the availability of state data allows anyone to challenge invalid state transitions or produce blocks to prevent censorship.
How do data availability layers work with modular blockchains?
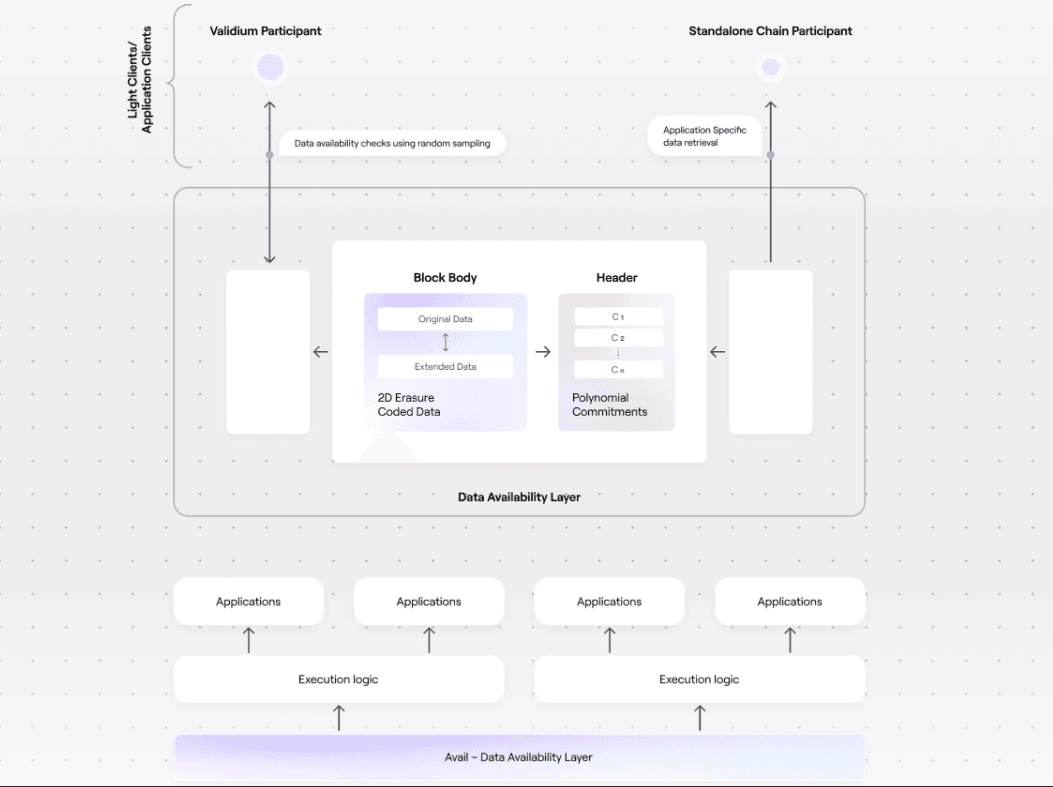
A modular blockchain is a blockchain that handles a specific function, such as execution, consensus, or data availability and relies on other blockchains and off-chain systems to perform the remaining tasks. The modular blockchain stack comprises different modular chains that work together in different ways to achieve set objectives.
The data availability layer in a modular blockchain stack is usually responsible for storing transaction data, although it may also provide consensus on the ordering of transactions. For example, modular blockchains that focus on execution (e.g. rollups and validiums) rely on off-chain data availability layers to store data behind state updates.
A data availability layer itself is a modular chain since it concentrates on storing data and outsources execution to other chains. Unlike regular blockchains, a pure data availability layer will not check the validity of data published by block producers. Nodes only have to come to consensus on the ordering of transactions and confirm that the right fees were paid.

What do data availability layers mean for Web3 developers?
The existence of a separate data availability layers has important benefits for blockchain developers including faster development cycles and cheaper user fees.
1. Faster development cycles
Developers launching new blockchains or application-specific chains can achieve meaningful security properties from the start by using a data availability layer. A blockchain’s security is usually measured by the distribution of validating nodes, but achieving an ideal distribution of validators in the early stages is unrealistic.
Instead, these new blockchains can focus on execution and settlement while relying on existing data availability networks for security. So, even if a small number of nodes are executing the chain, their capacity to act maliciously by publishing invalid transactions and censoring users is limited.
This is because state data needed to compute fraud proofs and validity proofs in order to verify execution is guaranteed to be available. Data availability also makes it easier to sync to the blockchain’s state, which is a requisite for producing new blocks.
2. Cheaper user fees
Competition for limited blockspace on Ethereum has driven transaction fees up, which is not ideal for decentralized applications (dApps) that need to post a large amount of data on-chain. Instead of publishing data on Ethereum, a dApp can cheaply store data on a layer optimized for data availability.
Fees for using data availability layers are lower for two reasons: nodes need to charge less fees to recover hardware expenses, and data availability networks can increase block size which means more transactions can be included in blocks.
1. Nodes need less expensive hardware
Nodes are only concerned with data storage and don’t need to invest in the bandwidth or hardware necessary for executing transactions. As such, nodes aren’t under pressure to charge high fees to recoup the investment in hardware.
2. Data availability networks can increase block sizes
Data availability networks can increase block sizes without harming decentralization and security due to data availability sampling.
Data availability sampling allows nodes to randomly sample a block to confirm its availability without downloading all of the data. Lower competition for blockspace means storing data on a data availability blockchain is cheaper on average.
What are the different types of data availability solutions?
Solutions to the data availability problem usually take two approaches: modifying on-chain data storage or storing data off-chain. We explore the two classes of data availability solutions below.
1. Modified on-chain storage
Modified on-chain storage requires changing how data is stored on-chain to achieve efficiency and security. A form of modified on-chain storage refers to the data sharding process discussed earlier.
In sharded blockchains, nodes only download and store data posted in a specific shard. In other words, validators run a full node for one shard and act in a light-client capacity for other shards.
The obvious question here is: “How can nodes be sure that the data for other shards is available without downloading those blocks?”
This is where data availability sampling enters the picture.
What is data availability sampling (das)?
Data availability sampling is a mechanism for verifying a block’s availability without needing to download all of it. Nodes apply data availability sampling by downloading random parts of a block to see if they’re available.
With many nodes randomly sampling a block, the probability of hiding block data reduces. If a node discovers a chunk of the block is unavailable, it can raise an alarm and alert other nodes.
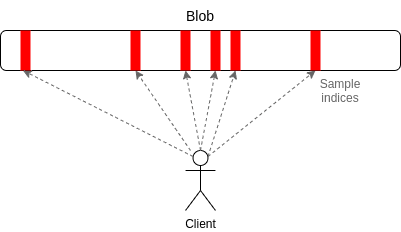
While data availability sampling can give nodes high statistical certainty that a block’s data is available, it cannot completely rule out data withholding attacks. A data withholding attack happens when block producers propose new blocks but don’t publish all of the transaction data.
Even if a block producer publishes most of the block, hiding a tiny fraction of the data still has security implications. What if a rollup operator performs an invalid transaction transferring a large number of users’ tokens to themselves and withholds data needed for challenges?
To have higher security guarantees against data withholding, we combine data availability sampling with erasure coding.
What is erasure coding?
Erasure coding is a cryptographic primitive for increasing the integrity and availability of data that involves doubling a dataset by adding redundant pieces (called erasure codes), such that any combination of the redundant pieces can help recover the original data.
Shard chains in Ethereum publish transaction data using “blobs” (binary large objects), which are similar to blocks. Before publishing a blob, the block producer must extend the original data via erasure coding. This way, anyone can reconstruct the entire block with access to some of the erasure codes.
Erasure coding makes it harder to perform data withholding attacks. With erasure-coded blocks, nodes only need a tiny fraction to recover the original data. Thus, a block producer would need to hide a large portion of the entire data set—more than 50%—to successfully hide data.
2. Off-chain data storage
Off-chain data storage involves storing data elsewhere to avoid burdening nodes. Off-chain data storage solutions are two-fold: data availability committees (DAC) and data availability networks.
1. Data availability committees (DACs)
A data availability committee (DAC) is a collection of permissioned entities tasked with holding copies of blockchain data offline. The DAC is often made up of trusted entities that are appointed to the role.
Block producers are required to send transaction data to members of the DAC when performing state transitions. This reduces centralization risk because the DAC can make the data available to users—especially if the block producer starts acting maliciously.
Validiums, which is an Ethereum scaling solution similar to ZK-rollups, use DACs to guarantee data availability. In addition to computing zero-knowledge proofs to verify transaction batches, block proposers must obtain attestations (signatures) from members of the DAC. This "availability proof" is verified along with the validity proof on Ethereum before new transaction batches are accepted.
Examples of projects using DACs include DiversiFi and ImmutableX.
While data availability committees help solve the data availability problem to an extent, they have certain drawbacks. The DAC is often small in size, making it easy for malicious actors to compromise the group. And because members of the DAC are "trusted" entities, there is no system to punish misbehavior in place.
2. Data availability networks
Data availability networks aim to decentralize the process of storing blockchain data and to remove trust assumptions. Data availability networks are similar to data availability committees, except for three key differences: permissionless architecture, trustlessness, and fault tolerance.
Permissionless architecture
The data availability network is usually a blockchain with the sole purpose of ordering transactions and storing data.
Data availability networks, like Celestia and Polygon Avail, use a Proof-of-Stake system that allows anyone to become a data availability manager. To do so, users only have to put up the required stake to start participating in the blockchain.
Trustlessness
Proof-of-Stake data availability networks use crypto economic incentives to ensure nodes act honestly. Every node tasked with storing data must stake some funds in a smart contract, which can can be slashed if they fail to provide data on request. This feature removes trust assumptions that exist with data availability committees.
Fault tolerance
Proof-of-Stake data availability networks often have higher participation sets than data availability committees. This makes it harder for malicious actors to compromise the group and conduct data withholding attacks.
Conclusion
Data availability plays a key role in the ability of blockchains to remain functional and secure. Especially within the context of modular blockchains, data availability layers allow for meaningful decentralization and security.
Ethereum’s future scalability plans also rely on its data storage capacity. Rollups are limited by data throughput on the parent chain, hence the introduction of data sharding and other upgrades to improve Ethereum’s performance as a data availability layer for Layer 2 solutions.
Related Overviews

What is Blockchain Sharding and How Does it Relate to Ethereum?
Learn About Safe (Justified), Finalized, and Latest Commitment Levels
Learn How Ethereum Transactions are Propagated Across the Ethereum Network

Build blockchain magic
Alchemy combines the most powerful web3 developer products and tools with resources, community and legendary support.