
Blockchain Data Deep Dive
Written by Mylene Tu
Reviewed by Logan Ross
Each Blockchain holds an immutable record of transactions and events. Web3 applications rely on blockchain data for alerts, dashboards, decision-making, or coming up with new features. It is critical to web3 as it powers everything from decentralized applications, to infrastructure, and NFTs.
This guide will cover all aspects of blockchain data, from onchain and offchain data, to blockchain indexing and subgraphs. By the end of this guide you should have a deeper understanding of how blockchain data is created, stored, and accessed.
What is onchain data?
Onchain data is simply all of the information stored on a blockchain network. It is the immutable record of all transactions that have ever occurred on the network and is publicly available for all to see. There are many different types of onchain data such as:
Transaction data: this covers information regarding each transaction on the blockchain such as the sender and receiver, value of transfer, and transaction fees.
Block data: this covers information about each block on the blockchain such as the hash of the previous block, transactions included within the block, the timestamp of the block, as well as miner fees and rewards.
Smart contract data: this covers information about all of the smart contracts that have been deployed on the blockchain such as the contract code itself, the state of the contract, and the events emitted by the contract.
Unlike offchain data, onchain data cannot be altered which is important in obtaining a holistic view of a blockchain network. This data can be used to track the movement of assets on a blockchain, verifying that transactions have gone through successfully, and generating insights into network activity.
The challenge with onchain data is that accessing it effectively can be cumbersome. Despite it being readily available, onchain data is encoded in a machine-readable format; this prioritizes security but sacrifices human-readability. Human-readable formats can be types like JSON and XML, which is where ABIs (application binary interfaces) come into play.
How are data structures defined?
As mentioned previously, onchain data is not stored like regular data. Instead, it is often stored in machine-readable formats such as bytecode.
ABIs (application binary interfaces) help developers monitor and decode the data into a human-readable format. Data structures in smart contracts are defined using the ABI. The ABI acts as a function selector that helps define how to interact with smart contracts, as well as the data types that each function accepts and returns. In other words, it is a standard way to represent data structures in a way that is easily understood by both humans and machines.
Where is blockchain data stored?
Blockchain data is generally stored in a distributed ledger meaning that it is not stored in a single location but rather on a network of nodes. Nodes are a fundamental component of storing and ensuring security of blockchain data as each node maintains a copy of the data. Outlined below are a few different types of nodes and how they work at a high level:
Full nodes: as the name suggests, full nodes store the entire blockchain history as well as the latest state of the network (the latest 128 blocks). The most recent state is what all clients need to verify incoming transactions. All previous states can theoretically be derived from a full node, however, this uses a significant amount of computational power. Developers should query full nodes for data when they need to access the most recent data and state of the blockchain. For context, on Ethereum the average time to produce a new block is about 13 seconds, you can only retrieve the chain states from the last 28-29 minutes.
Archive nodes: in addition to the complete blockchain history, archive nodes also maintain a record of the historical state of every block. This allows archive nodes to serve requests for historical data a lot more efficiently compared to full nodes. Developers should query archive nodes when historical data is needed as it does not require state regeneration like full nodes do. For developers that create analytics tools and other tools that require fast history access, archive nodes are ideal.
Light nodes: these nodes are ones that only store block headers; the minimum data needed to transact on the network. Developers may choose to query from light nodes when retrieving basic blockchain data from block headers.
Nodes are not the only way to store data. Data can also be stored offchain in databases, cloud storage services, or even on-premise servers. Storing data offchain may not be as secure as onchain, however, it is still useful for many applications as it is cheaper and faster to access. When data is stored offchain, typically only the information needed for locating the offchain data is stored on the blockchain.
Smart contracts & blockchain storage
Smart contracts are stored on the blockchain within nodes however, smart contracts themselves have mechanisms for data storage. Data is stored in smart contracts on something called contract storage layout. Contract storage layout refers to the rules governing how contracts’ storage variables are laid out in long-term memory.
For Solidity (a high-level programming language for building smart contracts), there are 3 different types of memory that can instruct the EVM on where to store their variables: memory, calldata, and storage.
Memory: this is used to store temporary data this is needed during the execution of a function
Calldata: this is a special data location that contains function arguments
Storage: this is where data is permanently stored on the blockchain
Data Storage vs. File Storage
Data storage in its simplest form is the process of saving data so that it can be retrieved and used later. File storage on the other hand, is separate from data storage when the actual files are stored in a different location than the metadata about the files. This separation is typically done to improve performance, reduce costs, or improve security.
A common way to separate file storage from data storage is by using a decentralized file storage system such as IPFS or Arweave. These systems allow users to store files on a distributed network of computers and can be cost-effective by reducing the amount of data that needs to be stored on the blockchain itself.
At a high-level, metadata about the file is stored onchain, while the file itself is stored offchain. When an application needs to access the file, it can retrieve the IPFS or Arweave URL from the metadata. The application can then use this URL to download the file from IPFS or Arweave.
What is IPFS?
IPFS uses a content-addressed system where each file is identified based on a CID (content identifier). CIDs are unique hashes that always refer to the same file, regardless of where it is stored.
This means that if the file changes or gets updated, the hash will also change. This content-addressed system allows files to be stored and retrieved based on their CID, rather than their location.
The general flow for how IPFS works is as follows:
A CID is created for the file
File is then uploaded to the IPFS network
IPFS stores information about which node in the network possesses the file associated with the CID in a DHT (distributed hash table)
The DHT can then be queried with the hash to find the node storing the file
The CID is stored in the token smart contract
Arweave
Arweave is another distributed storage solution that also uses CIDs to store and access content, as well as reference content in metadata. The main difference is that Arweave takes a different approach to incentives and permanence by incentivizing nodes to hold the data permanently.
Data Publishing vs. Data Storage vs. Data Availability
To gain a better understanding of blockchain data, we must also understand what data publishing, storage, and availability mean. To define these terms simply: data publishing is the process of making data available to others on a blockchain, data storage is the process of keeping data on a blockchain, and data availability is the assurance that data can be accessed by all participants on a blockchain network.
Data availability is important because when validators add blocks to the Ethereum blockchain, they must broadcast all the transaction data for that block to the other validators on the network. Validators are tasked with executing all of the transaction data which means that blockchains can only handle as many transactions as its validators can execute - this, in a nutshell, describes the data availability problem.
One of the core data availability problems is knowing whether or not a block was published without having access to the entire block (data publishing).
The main challenges with data publishing are that block producers will not produce blocks on top of blocks containing unknown content. This means that blocks with non-published data may be ignored altogether. Data storage enters the picture once the data is published, however, it is unclear how long the data will be stored by full nodes.This can be concerning as we cannot force nodes to keep the data, thus adding more concerns towards data availability.
Modular Blockchains and Alternative Data Availability
Modular blockchains are blockchains that tackle specific functions. For example, a modular blockchain may focus on data availability while relying on other blockchains or systems for other tasks such as execution or consensus.
Modular blockchains create alternative data availability layers to make publishing calldata cheaper than posting it to Ethereum by using a variety of techniques such as offchain data storage, data compression, sharding, and more.
One example of a modular blockchain that uses an alternative data availability layer is EigenDA. EigenDA is a decentralized data availability layer that is built on top of Arweave. EigenDA allows users to publish calldata to Arweave and then prove to Ethereum that the calldata has been published. This allows users to publish calldata to Ethereum without having to pay the high gas fees associated with storing calldata onchain.
Types of Onchain Data
Now that we’ve covered what onchain data is, we’ll dive deeper into the different types of onchain data and how they are generated, stored, and accessed.
What is transaction data?
Transaction data contains all information related to a transaction on the blockchain such as:
Sender
Receiver
Amount of transfer
Transaction fee
Timestamp of the transaction
This data is generated whenever a user makes a transaction on a blockchain. It is then broadcasted to the network nodes to validate the transaction and add it to the ledger.
Transaction data can be stored and verified by a type of tree data structure called Merkle trees. Merkle trees are binary trees that allow for fast data verification, where each node in the tree is a hash of the data that it contains. To verify the integrity of the data in a Merkle tree, all you need is the root hash of the tree. Storing data in Merkle trees is helpful in keeping the size of the blockchain as small as possible. Since there is a lot more detail that can go into Merkle trees, you can read more about Merkle trees in the Alchemy docs. For Ethereum in particular, data is stored using Patricia Merkle Tries- a combination of a radix trie (Patricia trie) and a Merkle tree.
When it comes to quickly accessing transaction data, you can simply use a blockchain explorer such as Etherscan for Ethereum transactions. Blockchain explorers allow users to view and search for all transaction data and can be used to track the movement of tokens, identify fraudulent transactions, develop blockchain applications, and more. In order to find data about a specific transaction, you will need the transaction hash. If you need to routinely access blockchain data for your application, Alchemy can help.
Metadata
Metadata is data that provides additional information about the transactions and assets on a blockchain. This could include additional details such as:
the name or symbol of an asset
the total supply of an asset
the ownership history of an asset
the contract address of an asset
Unlike transaction data, metadata is not essential for the operation of a blockchain but it is useful for developers in creating applications like block explorers, wallets, and dashboards to name a few examples. Metadata can be generated automatically as defined by the smart contract or blockchain (e.g. transaction metadata), or manually as defined by a user (e.g. asset metadata).
In order to access metadata, developers can use getMetadata queries. To use these queries, developers need to use a blockchain API such as the Alchemy API. By using getMetadata queries, developers can build a variety of applications that can help users to understand and interact with blockchain networks.
Events Data
Events data refers to the data that is emitted by smart contracts when they execute transactions. This data can include information such as:
The type of event that occurred
The address of the smart contract that emitted the event
Details about the event (e.g. the amount of tokens transferred, new owner of the asset, etc.)
This information is helpful in allowing developers to monitor the activity of a smart contract and can be accessed via logs. Logs are records of all the events that have occurred on a blockchain and are generated by smart contracts. These logs can be found on transaction receipts and can be viewed by making a request to eth_getLogs.
Calldata
Calldata is the data passed to a smart contract when a function is called. In other words, it is a form of temporary data storage where function arguments from an external caller are stored before being passed into the smart contract. Calldata can contain any type of data, whether that be integers, strings, arrays, and more. It is important as it allows smart contracts to communicate with each other and with users; for example, calldata could be used to transfer ownership of an NFT to a user in an NFT smart contract.
Gas fees are charged for all operations on the blockchain and using calldata is no exception. When an L2 transaction is posted to Ethereum, the call data is included in the transaction. This is because the call data is necessary for the Ethereum network to verify the transaction and to execute the smart contract function that is being called. The gas used by the call data is determined by the size of the call data and the type of data that is contained in the call data. For Ethereum, the max calldata each block can contain is 1,048,576 bytes.
Blobs
Blobs (binary large objects) are designed to make transaction verification more efficient through having the network confirm that the blob attached to a block carries the correct data. Blobs have been introduced in relation to proto-danksharding, a proposal to reduce calldata costs and increase calldata size per block.
Proto-danksharding is said to make calldata cheaper in blockchain by introducing a new type of transaction called a blob-carrying transaction. Blob-carrying transactions are similar to regular transactions, but they can contain data blobs.
Blob-carrying transactions are cheaper than regular transactions because they do not require as much gas to process. This is because the data blobs are stored offchain and do not need to be included in the transaction.
The introduction of data blobs and blob-carrying transactions will make it possible to store and process large amounts of data on the Ethereum blockchain more cheaply.
What is blockchain indexing?
An index in a book contains the page numbers where key words and ideas are mentioned. Similarly, blockchain indexing is the process of organizing and storing blockchain data in a way that makes it easy to search and query. This is important to understand when it comes to blockchain data because it allows users to access and analyze the data in a more efficient and effective way.
Since blockchains follow a time-ordered structure, the data can be scattered across numerous blocks and can become entangled. Indexing aims to solve this problem by creating an index of blockchain data.
This index is a database that stores a subset of the blockchain data in a way that is optimized for searching and querying. To index the data, there are multiple different indexing methods such as: indexing transactions-related information, indexing addresses, indexing smart contrat interactions, and more. The indexed data can then be accessed by developers through APIs provided by GraphQL, Alchemy, and other web3 protocols.
Common Indexing Use Cases
Now that we know how useful blockchain indexing is for developers to search and query data more efficiently, let’s look into a few common use cases of indexing.
Indexing transaction history - this can be used to track the trading volume and liquidity of things like the Uniswap pool, as well as to identify the largest traders and whales.
Indexing for analytics and reporting - this can be used to generate reports on various metrics such as transaction volume, gas fees, and user activity. It can be especially helpful when tracking and analyzing the performance of a particular smart contract, cryptocurrency, market trend, or for understanding user activity (e.g. number of active wallets, number of transactions processed, etc.)
Indexing metadata - this can be used to track the ownership and transfer of NFTs. A practical example of this could be an NFT analysis tool where you can query against an index of transactions for a specific NFT collection to understand the purchase/ownership history among other relevant details.
Indexing smart contract events - this can be used to track the movement of tokens (e.g. transfer events of a particular ERC-20 token), lending and borrowing activity, or to better understand the NFT market to name a few specific examples. Overall, indexing smart contract events helps us monitor the activity of smart contracts which can help with identifying weaknesses or even opportunities for new applications and services.
Offchain and onchain indexes
Indexes can be stored onchain or offchain, each with their own respective benefits and tradeoffs. Satsuma, for example, is an onchain indexing protocol acquired by Alchemy. Satsuma uses GraphQL, a query language for APIs and works by using subgraphs that scan network blocks and smart contracts to collect data from various sources in a single API call. Offchain indexing protocols work by either saving indexes in the local storage of a node (e.g. SubQuery) or through storing them in traditional cloud servers like AWS which can be faster than onchain indexing. With either offchain or onchain indexing protocols, developers can easily use querying languages:
GraphQL - a developer could use GraphQL to query subgraphs for the transfer history of a particular ERC20 token.
SQL - a developer could use SQL to query an offchain index for the list of all smart contracts that have been deployed on a particular blockchain.
Elasticsearch - a developer could use Elasticsearch to query an offchain index for the most popular NFTs on a particular blockchain.
How is blockchain data accessed?
Now that we’ve learned a bit about onchain data and how it’s stored, we can dig deeper into how blockchain data can actually be accessed by developers.
Querying Nodes
One of the most direct ways to access blockchain data is by querying nodes, however, this can also be the most resource-intensive.
To query nodes, you must use JSON-RPC to access the data via full or archive nodes (nodes that contain a complete copy of the blockchain as discussed earlier). To query a node using JSON-RPC, developers must send a JSON object to the node that contains the method you want to call, the parameters for the method, and the JSON-RPC version.
This can easily be done through solutions like Alchemy that provide a JSON-RPC API that can be used to query nodes.
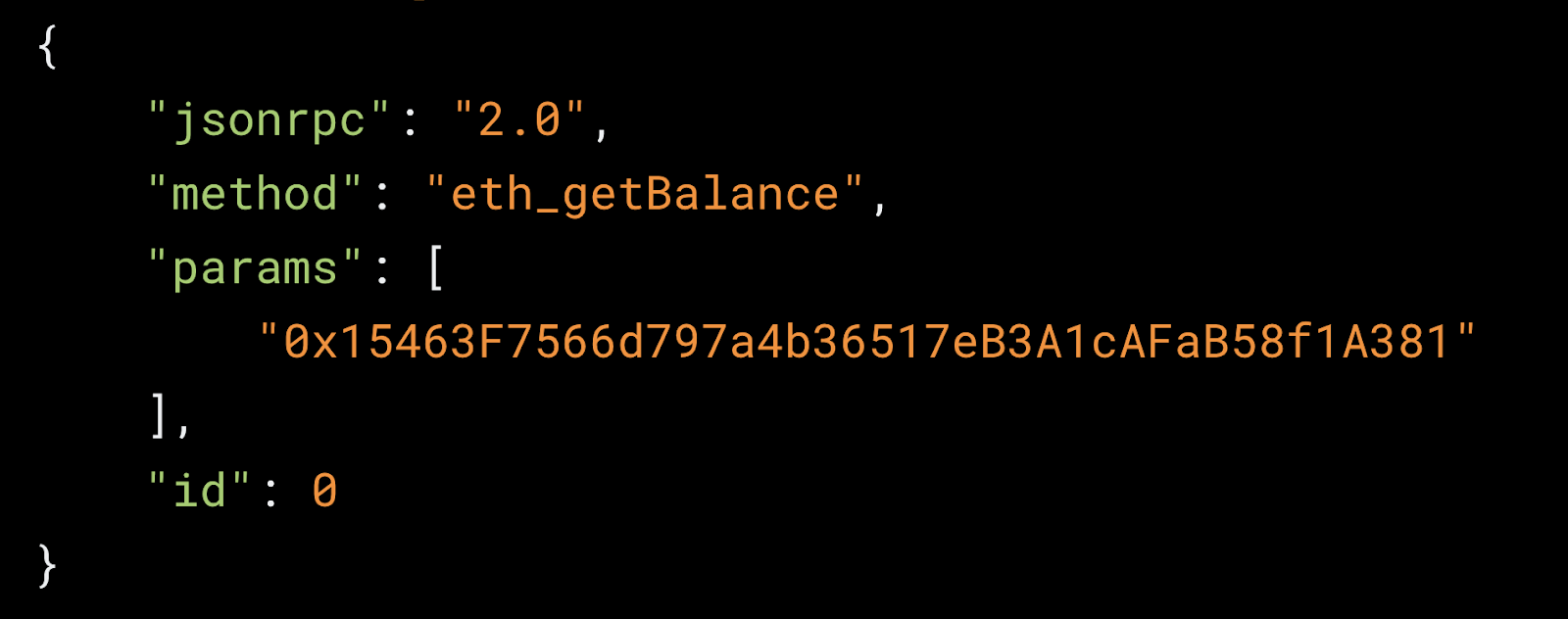
Event filters can also be useful when querying nodes for specific blockchain events. To use an event filter you need to specify the type of event that you want to filter for and the parameters of the event. An easy way to use event filters is through Alchemy Supernode. Alchemy Supernode is a fully managed service that includes all the infrastructure to run a node as well as APIs and SDKs that make it easy to interact and query nodes.
Streaming Data with Webhooks
Streaming data with webhooks is a way to receive real-time updates about blockchain data. Event data can be streamed using custom webhooks and webhook variables. This is done by choosing a blockchain indexing service such as Alchemy, creating a webhook endpoint on your server, subscribing to the events, and configuring the webhook variables. Alchemy in particular allows users to create custom webhooks that can be triggered by a variety of blockchain events, such as new transactions, new smart contract deployments, and changes to smart contract state. Alchemy has also recently upgraded their custom webhooks to help developers narrow data streams for better precision, and easily update webhook queries using variables.
Querying Subgraphs
Subgraphs are open-source APIs that are created by the community and are used for retrieving blockchain data from Indexers, Curators, and Delegators. Since subgraphs are built using GraphQL, developers can use the GraphQL API to query the subgraph. Subgraphs can be hosted or self-hosted. Hosted subgraphs can be queried by sending a GraphQL query to the GraphQL API URL. Self-hosted subgraphs can be queried by deploying the subgraph to the GraphQL server. This can be done through solutions like Satsuma that allow developers to deploy their own subgraphs.
Querying Data Warehouses
Data warehouses are optimized for querying historical data, usually in a structured format. Data lakes on the other hand store large amounts of data that are typically unstructured or semi-structured. Dune Analytics is a tool that can be used to query, extract, and visualize data from data lakes. Dune does this by providing tools such as their dataset explorer, allowing you to explore data on different chains, datasets, raw blockchain data, and more. You can also create your own data lake by backfilling a database and streaming data via custom webhooks.
Conclusion
In summary, understanding blockchain data is useful for any developer looking to use or build web3 infrastructure or applications. Onchain data is stored on the blockchain and can be broken down into different types such as transaction data, metadata, events data, calldata, and blobs. This data is then stored in nodes and can be accessed through a variety of ways depending on one’s use case.

Related overviews

Everything You Need to Know About RPC Nodes for Building Onchain
Explore the Best Blockchain Node Infrastructure Providers for Building Onchain.
Learn About The Tokenization Initiatives and Why Banking Institutions are Tokenizing Their Assets
